CHORUS and AGU held a lively forum on Friday, 17 June 2022 to discuss how to make the interoperability and reusability data goals of FAIR a reality. 
This forum was sponsored by ACS Publications, AIP Publishing, Royal Society of Chemistry, SPIE, and Silverchair. Shelley Stall, Senior Director for Data Leadership at AGU, moderated the event.
Stall opened the forum with a review of the FAIR Guiding Principles, noting that communities across all disciplines have been grappling with ways to make data and other digital objects more Findable, Accessible, Interoperable, and Reusable (FAIR). Good progress has been made toward making data findable and accessible, and those goals seem achievable. However, interoperability and reusability are areas that are incredibly difficult and complex.
The first session focused on why reusability and interoperability are important goals, discussed the challenges in actually making them a reality, and explored ways in which the scholarly community can work together to progress those goals.
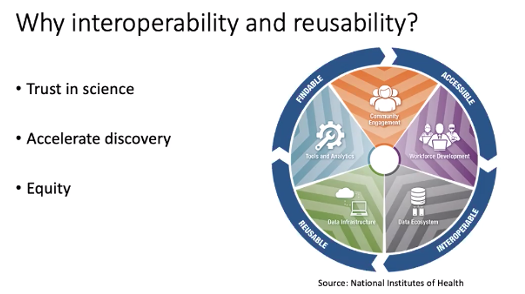
Christopher Marcum, (bio) Assistant Director for Open Science and Data Policy, White House Office of Science & Technology Policy focused his presentation on digital data sharing (as opposed to physical samples, lab notes, etc.) from a policy and practice perspective. Marcum posited three key reasons to value interoperability and reusability, to build trust in science, to accelerate discovery, and to advance equity. He suggested several areas where the community can innovate to advance these goals:
- opening up and bridging between silos,
- building (upon) infrastructure needs,
- setting consistent standards,
- training emerging and established users,
- support for retooling labs
 Marcum also discussed the need for thought leadership on the ethics of how one aspect of open data fairness may spill over into other aspects. Striving towards interoperability and reusability may help temper some of the downsides of quick shifts in funding tides or popular enthusiasm for an emerging paradigm.
Marcum also discussed the need for thought leadership on the ethics of how one aspect of open data fairness may spill over into other aspects. Striving towards interoperability and reusability may help temper some of the downsides of quick shifts in funding tides or popular enthusiasm for an emerging paradigm.
There is an opportunity to ensure that data models and ontologies seeking greater interoperability and reusability standards build in safeguards for the validity and reliability of data.
Chris mentioned the following resources: the National Science and Technology Council subcommittee on Open Science recently released “Desirable Characteristics of Data Repositories for Federally Funded Research,” intended to be a living document for federal guidance.
Ingrid Dillo (bio) Deputy Director, DANS: Dutch National Centre of Expertise and Repository for Research Data and Co-chair of Council Research Data Alliance spoke about how sustainable development goals can really only be addressed through cross-domain research, or research that tries to understand the complex systems through machine assisted data analysis at large scale.
Dillo noted that during the pandemic we were confronted with an immediate challenge: while there was efficient IT in place to improve the global capacity to implement systems to share data, harmonization across sophisticated diverse systems still formed a major roadblock. Many outputs turned out not to be reusable or useful to different communities because they were not sufficiently documented and contextualized, or appropriately licensed. Continued implementation of best practices in data management and sharing is needed if we want to optimize the use of research data.
DANS is currently completing a project commissioned by the European Commission to survey the European research data landscape which will be published shortly. As part of this project, the FAIR data assessment tool (F-UJI) was utilized to assess the fairness of 8k datasets from 31 repositories across Europe. The results showed:
- the average FAIR score was only 54%
- the findability score was the highest at 78%
- and the reusability score was 38%
A survey of 12k European researchers was also conducted to quantify awareness of FAIR in relation to managing and sharing data. Around 70% of respondents said they were not familiar with FAIR, and only 18% noted that they had put those principles into practice.
According to the Figshare International State of Open Data 2021 report, there is more concern about sharing datasets among researchers than ever before. Both the European and Figshare surveys make clear that the main challenges are not technical, but are related to financial constraints, legal and data protection concerns, and issues around trust and lack of recognition. The time and effort required in making data FAIR is also an impediment.

“The European Open Science Cloud (EOSC) aim is only useful if it becomes part of a global interoperable system”, said Dillo. Here is a link to the EOSC interoperability framework: Report from the EOSC Executive Board Working Groups FAIR and Architecture
Follow the FAIR-IMPACT project on Twitter: fairimpact.eu and LinkedIn: https://www.linkedin.com/company/fair-impact-eu-project
The audience was asked to provide their input on the challenges of interoperability and reusability, here are the results.

Session 2 showcased solutions to make data interoperable and reusable that are being put into practices by the research community.
Corinna Gries (bio), Principal Investigator for the Environmental Data Initiative, reported that EDI operates with the long-tail  in mind, with a lot of research done individually, we have no standard methods, no standard data formats but plenty of units. EDI has been around for almost 10 years, but grew out of 40+ years of data management experience of the NSF funded long-term ecological research program where NSF required that all sites include data management, data archiving, data publishing, and that these data are being made available. Metadata standards were developed in collaboration with the National Center of Ecological Analysis and Synthesis of which came the Ecological Metadata Language (EML). Building on the metadata standard, the repository infrastructure was developed.
in mind, with a lot of research done individually, we have no standard methods, no standard data formats but plenty of units. EDI has been around for almost 10 years, but grew out of 40+ years of data management experience of the NSF funded long-term ecological research program where NSF required that all sites include data management, data archiving, data publishing, and that these data are being made available. Metadata standards were developed in collaboration with the National Center of Ecological Analysis and Synthesis of which came the Ecological Metadata Language (EML). Building on the metadata standard, the repository infrastructure was developed.
Based on the experience and work in the repositories, the different aspects of FAIR are evaluated in two dimensions (1) ease in finding and reusing data and (2) effort in metadata and data formatting. Measurements of FAIR are performed using various tools: user interviews; data use (downloads and citations); peer review data; and design patterns.
A common data reuse scenario in environmental sciences is a data synthesis project that only reuses public or shared data. For example, many datasets are harmonized into one product with the metadata file developed and deposited and cited in EDI. New datasets then spawn from those data synthesis products. This is not a very linear process and raises the question of whether it should be called reuse, data reuse, or data use? For design patterns, EDI has worked with scientists to find what it is that they could reuse. The conditions were to keep the original format and contextual information and automate updates. One result from this piece of work includes 70 datasets, and EDI is now evaluating to see if the exercise was worth the effort.
Jens Klump (bio), Group Leader for the Research Group Exploration Through Cover at Commonwealth Scientific and Industrial Research Organization (CSIRO) in Perth, Western Australia described his hypothesis of data in 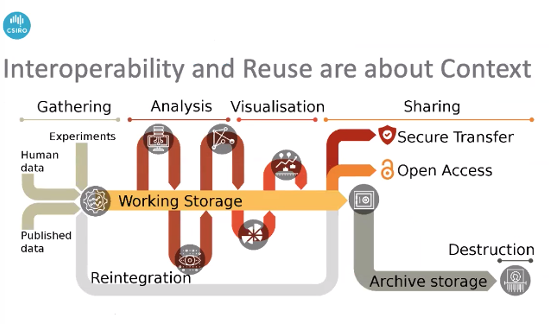 context with interoperability and reuse around gathering, analysis, visualization, and sharing. In order to make things sharable and determine if we do want to share, we have to understand what happened in the previous steps. Data is enriched throughout the data life cycle, from the private domain through to the public access domain. One must capture context along the way because adding it retrospectively is next to impossible. Data that sits in domain specific applications with specific domain metadata can then be tied together by knowledge graphs and persistent identifiers acting as anchors.
context with interoperability and reuse around gathering, analysis, visualization, and sharing. In order to make things sharable and determine if we do want to share, we have to understand what happened in the previous steps. Data is enriched throughout the data life cycle, from the private domain through to the public access domain. One must capture context along the way because adding it retrospectively is next to impossible. Data that sits in domain specific applications with specific domain metadata can then be tied together by knowledge graphs and persistent identifiers acting as anchors.
Klump noted that capturing data in the field by utilizing mobile data and encoding with a QR code to identify and tie the sample to the metadata is critical and allows for the automation of documentation. He suggests that to capture the context for reuse, let the machines do the heavy lifting and capture the context as you go through the metadata automation.
Useful links: faims.edu.au, igsn.org, and sensor.awi.de
Jane Wyngaard (bio), Lecturer in the Department of Electrical Engineering at the University of Cape Town presented on data design patterns which are a pragmatic and scalable approach to data and software management protocols. Advantages in design patterns in software engineering facilitate communicating complex problems, promote reuse, capture community practices, improve maintainability, and provide a structure that is known to work for a given problem class. Practical everyday examples of design patterns would be Nest thermostats, Bluetooth speakers, lights you can control within a command pattern applied to a smart home controller.  A reusable data design pattern concept would be a reusable data management template created to address how to practice FAIR for a common data type.
A reusable data design pattern concept would be a reusable data management template created to address how to practice FAIR for a common data type.
Data design patterns would exist for different data types/classes. Some advantages would be to reduce the cognitive load and address common problems. Data design patterns could be reusable across domains, but do not replace best practices, standards, or documentation.
A project in the works with AGU and CUAHSI will demonstrate a collaboration with the hydrology community to create a full design pattern with the components of FAIR at the forefront.
In closing the forum, Stall reiterated that high-level policy encourages change within our community — even if not mandated. Policy provides leverage to change directions/culture. Not every discipline has the same level of support. We need to have the tools and mechanisms in order to help researchers get to the point where their data is well documented to support interoperability and reusability.
Key opportunities for supporting interoperability and reusability are:-
- High-level policy to help drive the support within our community.
- Tools and mechanisms to help researchers get to the point where their data is well documented to support interoperability and reusability.
- Community guidelines that support researchers so they don’t have to guess what the policy is asking them to do.
CHORUS and AGU thank the panelists for their insights, our sponsors for their contributions, and the many attendees who participated and helped make this CHORUS Forum a success. The full recording of the event along with the individual presentations are available on the event page.
Links to the Q&A and Chat can be found here – https://www.chorusaccess.org/wp-content/uploads/CHORUS-Forum_-June-17-2022-QA-Chat.pdf