Ted Habermann, Metadata Game Changers
Jamaica Jones, University of Pittsburgh
Tara Packer, CHORUS
Howard Ratner, CHORUS
The Global Research Infrastructure (GRI) is made up of the repositories and organizations that provide persistent identifiers (PIDs) and metadata about many kinds of research objects (preprints, published papers, datasets, dissertations, proposals, reviews, etc.) and the connections between these objects and funders, research institutions, researchers, and one another. Together, this infrastructure currently contains millions of objects and is growing rapidly in almost every possible direction. How can this infrastructure increase understanding of the myriad contributions made to global knowledge by funders like the National Science Foundation and other federal agencies? How can we use this infrastructure to increase understanding of connections across the U.S. and global research landscape? How can this infrastructure be used to increase completeness, consistency, and connectivity within agency repositories and search tools? These are the kinds of questions we will explore in a new collaboration between Metadata Game Changers and CHORUS funded by the U.S. National Science Foundation.
CHORUS brings together funders, societies, publishers, and institutions from across the open research ecosystem to share knowledge, develop solutions, advance innovation, and support collective efforts. CHORUS retrieves data from across the GRI and provides open services for users — including search, dashboard and reporting services as well as a public API (CHORUS API). The reports are tabular data in formats accessible to common analysis tools.
The project involves four distinct phases, shown schematically in this Figure.
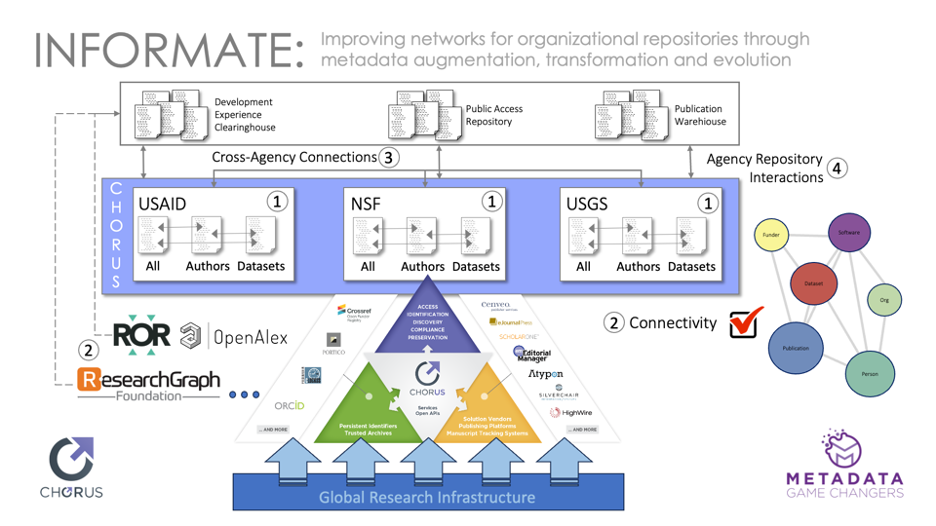
SCHEMATIC DIAGRAM OF INFORMATE PROJECT STRUCTURE AND TASKS
Phase 1: CHORUS Background
CHORUS provides reports for U.S. Federal Agencies that distill GRI metadata into easily digestible files. The first phase of the project (1 in the Figure) focuses on three reports and three agencies (NSF, USGS, and USAID). The goal is to provide a detailed description of CHORUS data reports and set stage for further analysis.
Key research questions:
- What reports are available from CHORUS?
- What properties are included in those reports?
- What internal connections exist between the reports?
- What external connections are/could be used as CHORUS data sources?
Phase 2: Funder, Organization and People Connectivity
Identifiers of many kinds facilitate critical connections between research objects, funders, organizations and people and provide a foundation for tracking research impact. The goal of the second phase is to determine quantitative baselines for Funder, Organization and People identifier coverage in the Global Research Infrastructure as represented by CHORUS data.
Key research questions:
- What persistent identifiers are available from CHORUS?
- How complete is the identifier coverage (i.e., connectivity)?
- How could the connectivity be improved? Is there low-hanging fruit?
- How could adding organizational identifiers improve CHORUS connectivity?
Phase 3: Funder and Cross-Agency Collaborations
CHORUS reports include information about multiple funders and, in many cases, datasets associated with specific research outputs. The goal of phase 3 is to use global research infrastructure metadata to discover collaborations between multiple agencies, organizations, and datasets.
Key research questions:
- What federal agencies collaborate by funding the same research outputs?
- What research organizations collaborate on creating research objects?
- What datasets funded by federal agencies are reused?
Phase 4: CHORUS and Agency Repositories
All three of the agencies we are including in this study support repositories of research outputs related to the agencies. The goal of phase 4 is to compare CHORUS and agency repositories to identify overlaps, differences, and opportunities for improvements.
Key research questions:
- How does CHORUS content vary across agencies?
- How does CHORUS content compare to agency repositories?
- What is the temporal relationship between funding and publication of results?
INFORMATE
The term informate was introduced during 1988 by Shoshana Zuboff in her book In the Age of the Smart Machine. It is defined as “the process that translates descriptions and measurements of activities, events and objects into information. By doing so, these activities become visible to the organization.”
The overall goal of this project is to understand and characterize CHORUS’ capability to make the vast and growing global research infrastructure visible and to help facilitate use of that powerful information resource for the entire research community.